면접 답변용이라고 생각하고 최대한 풀어서 쓰겠음
Attention
Attention이라는 용어는, 토큰의 시퀀스로 구성된 문장에서 토큰 간 얼마나 관련성이 있는지를 나타내는 용어입니다. 어텐션 매커니즘은 Query, Key, Value의 세 가지 벡터와 softmax함수로 계산되는데요,
\begin{equation}\label{atn}\tag{*}\text{Attention}(Q, K, V) = \text{softmax}\left(\dfrac{QK^\top}{\sqrt{d_k}}\right)V\end{equation}푸핫 이게 뭐람
- Query: '질문'이라는 의미를 가지고 있는데요, 어떤 토큰이 다른 토큰과 얼마나 연관성이 있는지 '질문'하는 역할을 해준다고 해요.
- Key: 그 질문에 대한 대답이라고 표현할 수 있을 것 같아요. 그래서 이 두 요소를 가지고 $QK^\top$ 연산을 하고 softmax 함수를 취해주면 토큰과 토큰 간의 관련성이 쭉 나오는데, 이 값이 높으면 우리는 한 토큰이 다른 토큰에 집중하고 있다(attend to)고 말한대요.
- Value: 3B1B 선생은 토큰 별 임베딩 스페이스에서, 우리가 원하는 구/문장을 표현하려면 특정 토큰 벡터가 얼마나 이동해야 하는지?를 의미하는 벡터라고 표현하더이다..
정확한 수학적 정의는…
Q = Query : t 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
_출처: https://wikidocs.net/65775
그래서 softmax값과 곱해져 계산된 attention 값은 단어들간의 관계를 반영해 전체 문장을 임베딩 스페이스 내에서 어떻게 표현할 것인가!에 관한 계산방법이라고 말할 수 있을 것 같아요. query, key, value 각각을 계산하기 위한 weight이 존재하고 이는 학습 시에 조정됩니다.
이 프로세스가 single 'head' attention을 지칭하고, GPT는 multi-head attention으로 구성되는데 이런 어텐션 계산이 병렬적으로 이뤄지는 구조예요. 문장 내에 존재하는 다양한 attention pattern을 캐치하자는 게 그 취지라고 할 수 있을 것 같습니다.
트랜스포머는 Attention layer => MLP (multi-layer perceptron) => Attention layer => ... 로 구성됩니다.
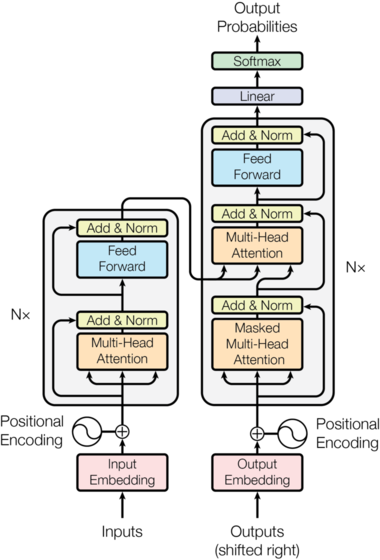
미친놈들 이런 걸 대체 어떻게 생각해냄
포시셔널 인코딩은 단어벡터와 더불어 문장 내에서 단어의 위치도 임베딩에 들어간다는 걸 의미하구요, self-attention이라는 표현도 종종 보일텐데 그것은 한 문장 안에 있는 단어들끼리 어텐션을 계산해준다는 이야기입니다.
이상~
'math4ai > Machine Learning and Deep Learning' 카테고리의 다른 글
| M4AI) BayesNet, Markov Chain, HMM (1) | 2024.07.31 |
|---|---|
| M4AI) Special Topics: MLDL Techniques (1) | 2024.07.31 |
| M4AI) Special Topics: Deep Learning, etc. (1) (1) | 2024.07.29 |
| M4AI) LDA & Ensemble (2) | 2024.07.29 |
| M4AI) Unsupervised Learning: Clustering (1) | 2024.07.28 |

