요즘 뜨는 LLM 소식~ Mixture of Experts (MoE)!
REF
- https://huggingface.co/blog/moe
- https://taewan2002.medium.com/mixture-of-experts-with-expert-choice-routing-5f829b36448d
LLM의 발전은 GPT 등장 이후 scale-up을 하다가(대표적인 예가 PaLM 등등..), 자원을 너무 잡아먹는 것 때문에 다시 모델을 scale-down 했었습니다. 그 era에 등장한 아이들이 아마.. Llama, gemma, mistral 같은 아이들이었던 것 같아요. 이 자원 문제를 계속 태클하면서 최근에 주목을 받고 있는 방법이 Mixture of Experts인 것 같군요~.~ 이 방법론이 제안된 건 좀 된 거 같은데 요즘 이쪽으로 논문이 많이 나오나봐요

두 가지 요소가 눈에 띄어요:
- Switching FFN Layer — 이전 계층의 모든 노드가 다음 계층의 모든 노드와 연결된 dense layer를 대체하는 녀석이라고 해요. Expert라 불리는 neural network들이 있다고 하는데, MoE도 될 수 있다는군요 (hierarchical MoE, MoE 안의 MoE 모 그런..)
o.O 몬소리래 - Router — Figure 2에 따르면, 라우터가 FFN을 토큰마다 할당해주고 있는 것을 알 수 있어요. 하나 이상의 expert를 할당해주기도 한다고 하네요! 얘도 학습된다고 하는군요 흠터레스팅.. 보통 소프트맥스 딸린 linear network라고 말하고 있습니다. 토큰 하나가 들어오면 얘가 소프트맥스로 가장 적절한(?) expert를 할당해주는 건가봐요.

와 나온 지 진짜 오래 됐구나
이쯤 돼서 드는 의문: 대체.. Expert를 왜 여러 개 쓰는 거야? => scale-up을 하기 위함입니다. 몇십 빌리언 파라미터보다 이렇게 하는 게 자원을 효율적으로 쓰면서도 모델의 파라미터 수를 끌어올릴 수 있는 방법이래요. 대표적인 예시가 바로 이 Mistral-8x7B!! Expert 각각이 Mistral-7B이고 이런 애들 여덟 개로 구성된 MoE layer를 썼다고 할 수 있을 것 같아요.
요건 MoE를 다룬 서베이 논문입니다: https://arxiv.org/abs/2407.06204
A Survey on Mixture of Experts
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse d
arxiv.org
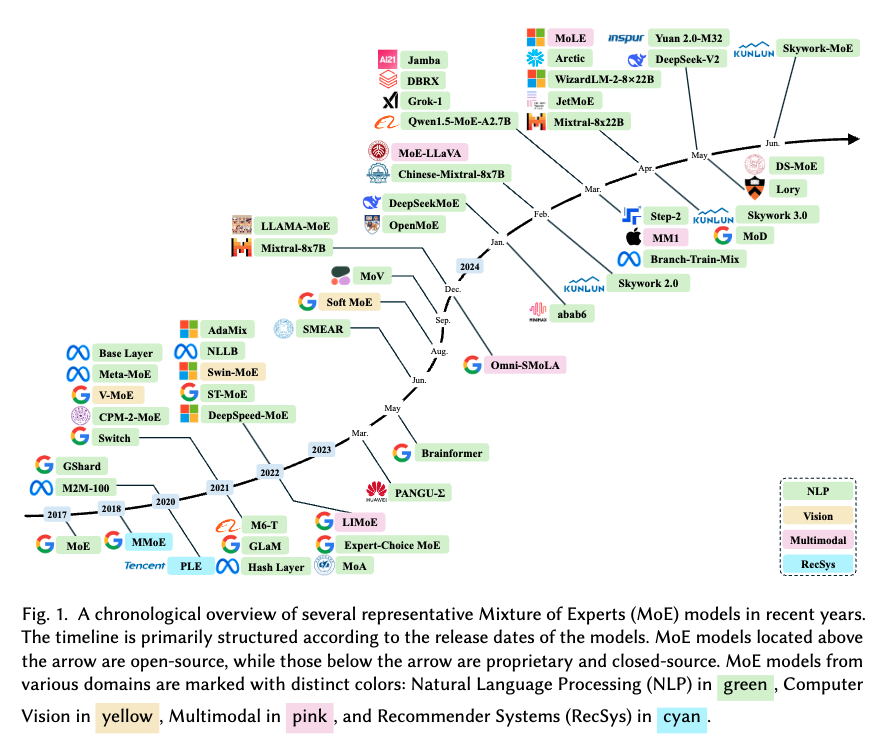
NLP에서 압도적으로 많이 시도하고 있고, 특히 구글이 주력하고 있나봐요.
아참 이 논문에 따르면 Dense MoE도 있고 Sparse MoE도 있다고 하는데, 차이는.. Router가 계산한 softmax를 top-k를 취해주는지 아닌지 차이입니다. 그림 보면 이해가 빠른데 음.. 토큰마다 Gate, 즉 라우터가 8개의 expert에 대해 softmax를 계산해주는데 (확률.. 너낌,,) Dense MoE는 이 값을 모두 활용 —normalize느낌으루— 해서 최종 output을 내는 반면에 Sparse MoE는 top-k에 해당하는 라FFN만 선택적으로 고른다는 특징이 있죠. 아무래도 후자가 더 비용효율적인 것 같음~

더 자세한 내용은 이 논문 참고하기.. 나 자신.. 언젠간 읽어볼거지..응?
근데 두 가지의 대표적인 문제점이 있나봐요:
- pre-training때는 괜찮은데, fine-tuning할 때 overfitting이 발생하는 문제가 있대요
- scale에 비해 inference 시간이 단축된다는 장점이 있긴 하지만, 이 뚱땡이 모델이 결국 RAM에 올려져야 하긴 하니까 RAM이 계속 터진다는 단점이 있어요ㅜ Mistral-8x7B의 경우 약 47B의 파라미터 수를 가지고 있기 때문에 (56B가 아닌 이유는 FFN 외의 파라미터는 다 공유하고 있어서!) 47B 모델보다 inference, pre-training 모두 시간과 자원을 다 절약할 수 있지만, 같은 크기의 VRAM이 필요하긴 합니다..
흠 더 공부하게 되면 채우러 오겠음
'newsie' 카테고리의 다른 글
| [Fortnightly Tech Digest] Special Topic: Agentic RAG (0) | 2024.11.24 |
|---|---|
| [Fortnightly Tech Digest] October-November Crossover (6) | 2024.11.08 |
| [Fortnightly Tech Digest] October's Second Half (9) | 2024.10.26 |
| [Fortnightly Tech Digest] October's First Half (1) | 2024.10.12 |
| KAN: Kolmogorov-Arnold Network (0) | 2024.05.19 |



